Release Versions: Link
SPA & Angular 2:
What is Advantages of Angular 2?
Angular 4 - Updates & New Features:
Angular 5 - Updates & New Features:
Angular 6 - Updates & New Features:
Angular 7 - Updates & New Features:
Ref:
- Angular JS: 2009
- Angular 2: May 2016
- Angular 4: Mar 2017 (To prevent conflict with router package version, skipped version 3)
- Angular 5: Nov 2017
- Angular 6: May 2018
- Angular 7: Oct 2018
- Angular 8: May 2019
- Angular 9: Feb 2020 - Moved all applications to use the Ivy compiler and runtime
- Angular 10: Jun 2020
- Angular 11: Nov 2020
- Angular 12: May 2021
- Angular 13: Nov 2021
Angular JS vs Angular 2:
- In 2009, AngularJS with Javascript, In 2016, Angular 2 with TypeScript & Dart
- In addition to tighter integration with Typescript, Angular 2 promises a better performance (5-10 times faster). Rationale
- Heavy Loading At Client Side:
- Typically, 90–95 percent of the application code runs in the browser. Only when the user needs new data or must perform secured operations such as authentication; work goes to the server.
- Because dependency on the server is mostly removed, it increase server availability.
- No matter how many users access the server simultaneously, 90–95 percent of the time the app's performance is never impacted.
- Also, because most of the load is running on the client, the server is idle most of the time.
- Low demand on server resources reduces stress on the server significantly, potentially reducing server costs.
- Seperate Layers: Application Layer and Rendering Layer
- Rendering performance is substantially improved in Angular 2.
- Most importantly, the fact that the rendering module is located in a separate module allows you to run the computation-heavy code in a worker thread.
- Keeping the rendering engine in a separate module allows third-party vendors to replace the default DOM renderer with one that targets non browser-based platforms.
- This allows reusing the application code (TypeScript Code Class) across devices, with the UI renderers for mobile devices that use native components.
- I.e. Code of TypeScript class remains the same, but the content of the @Component annotation will contain XML or another language for rendering native components.
- No more battling standards between html5 compliant data-ng-click or the short and sweet ng-click, they are replaced by (click) attribute with parentheses around it.
- Angular 2 is entirely Component-based UI & Service/Controller compared to Angular v1 MVC approach. Controllers and $Scope are replaced by Components and Directives. Also added Modules, Services, Routes etc.
- This helps dividing applications in terms of components with desired features which helped to improve the flexibility and reusability as compared to Angular v1.0
- Mobile Support: Angular 2.0 has made it possible to accomplish the native applications for a mobile platform like React.
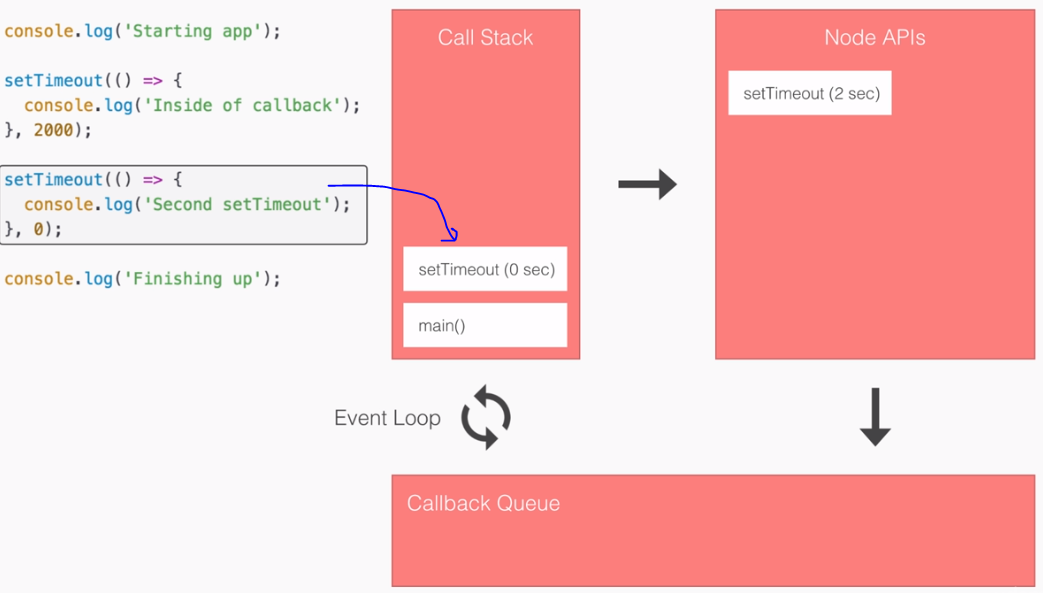
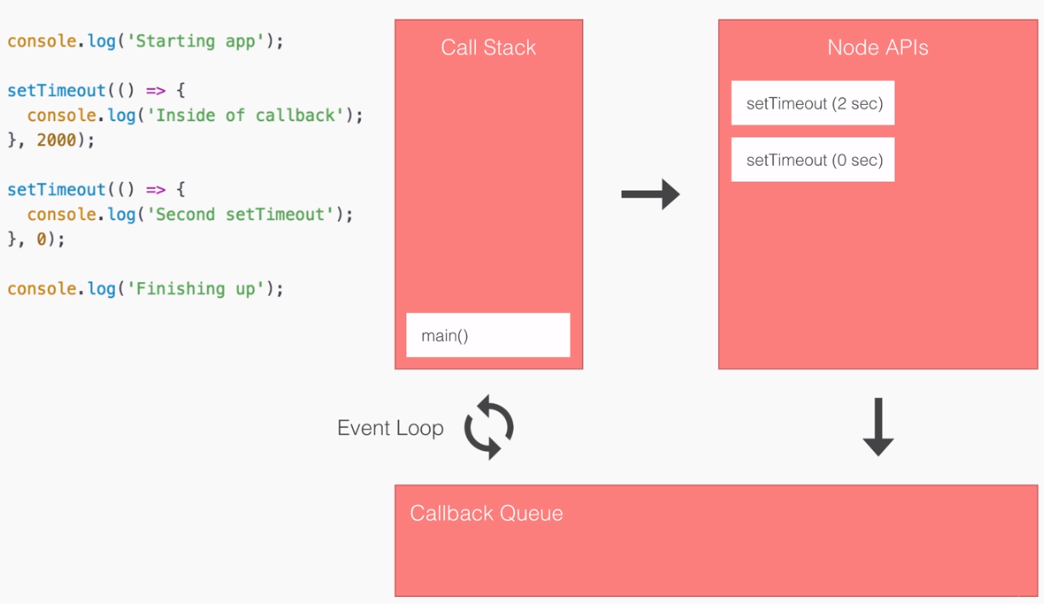
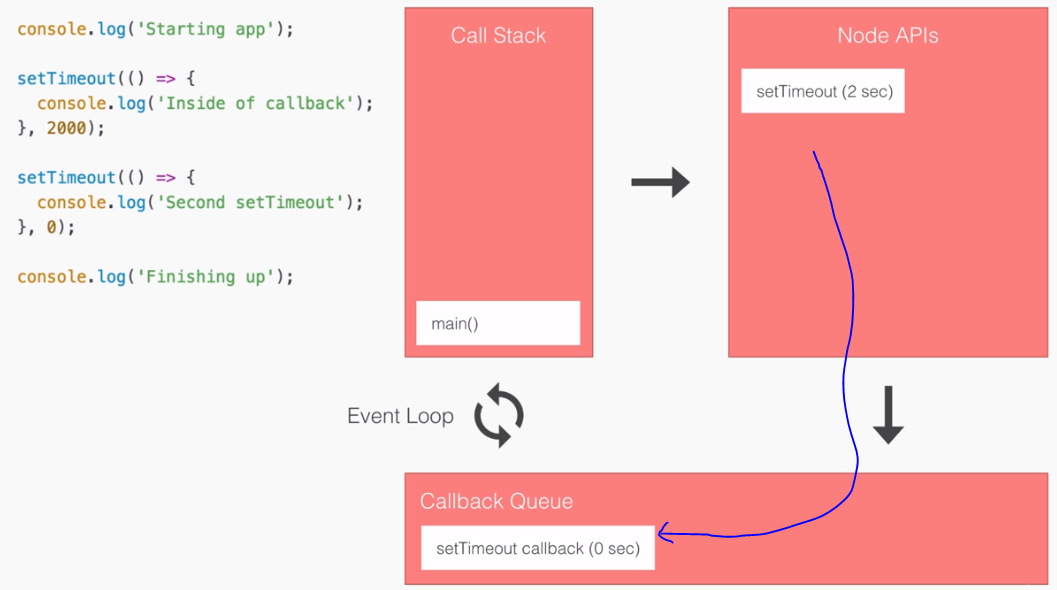
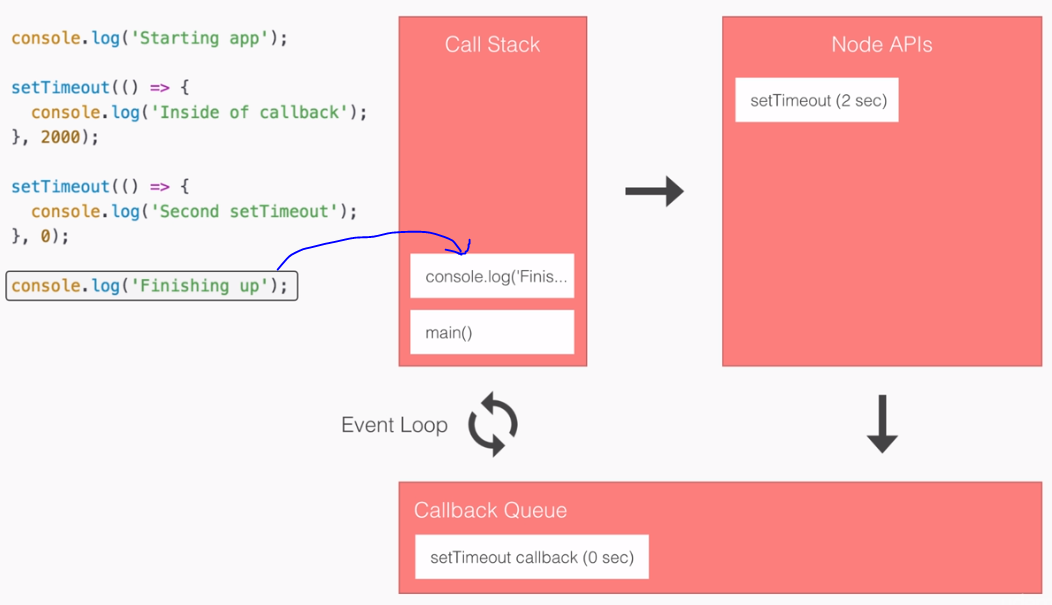
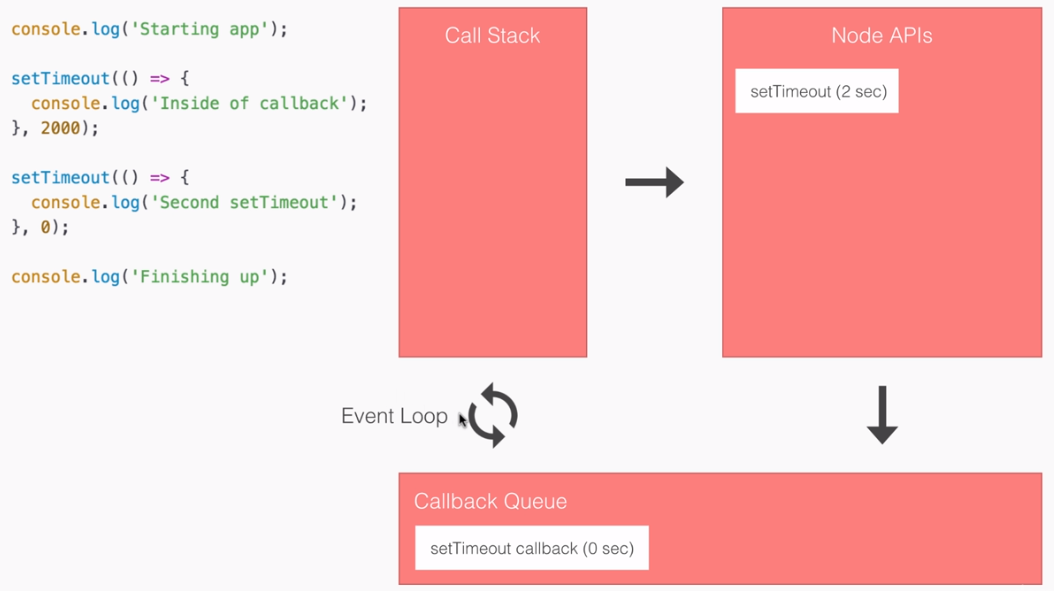
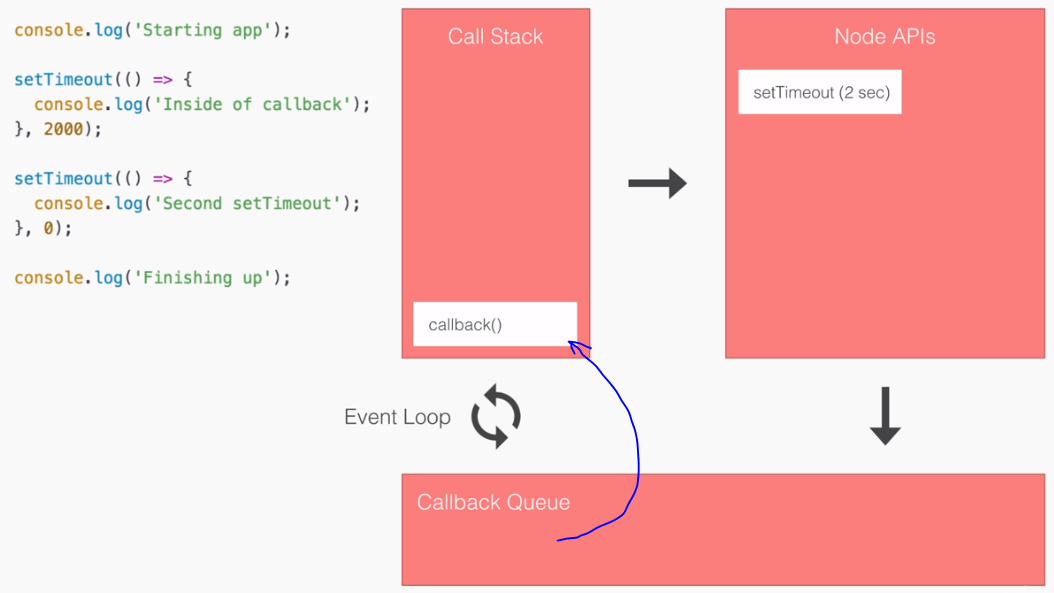
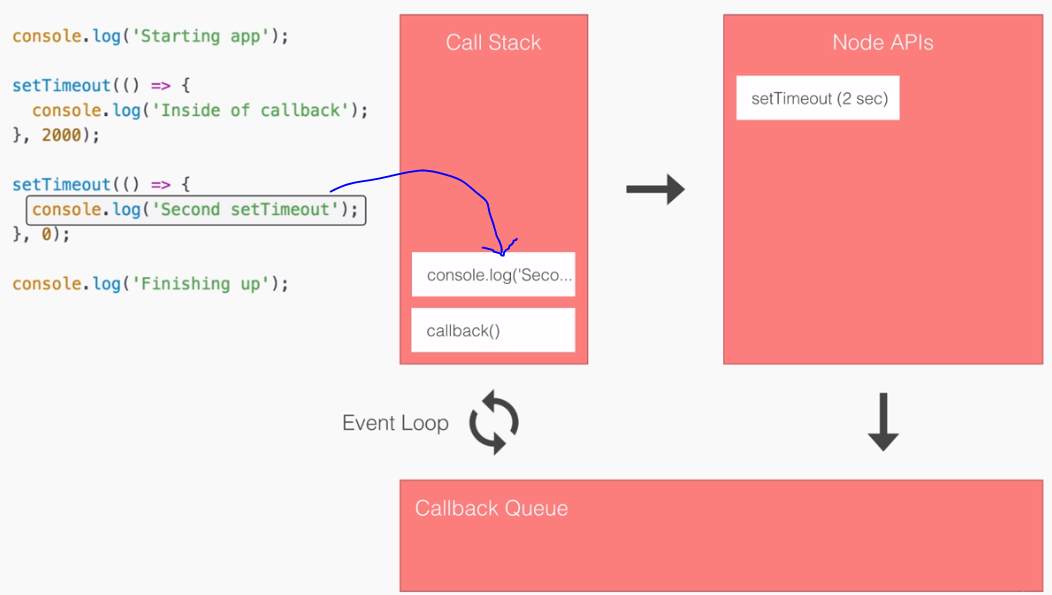
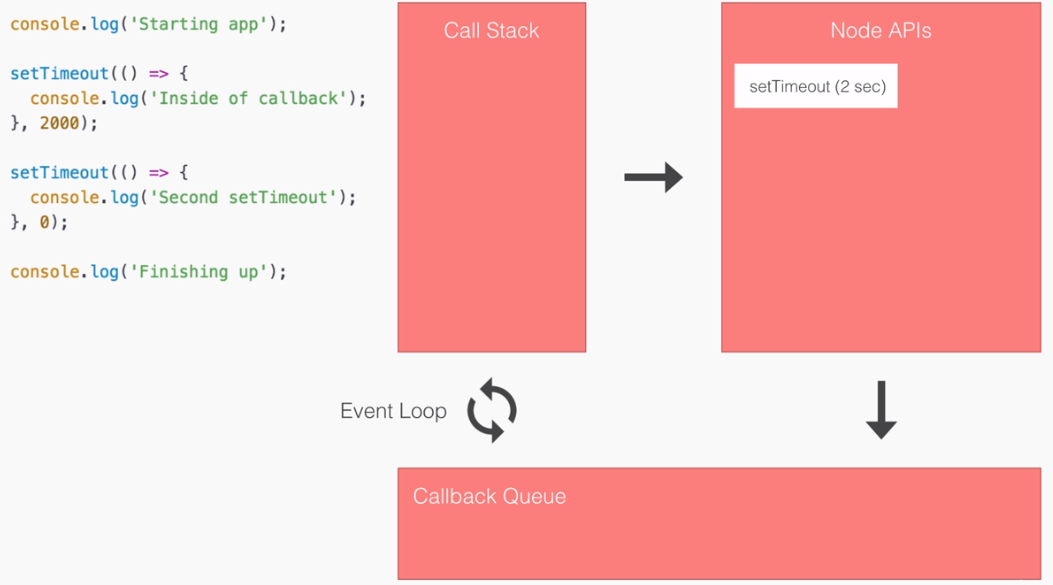
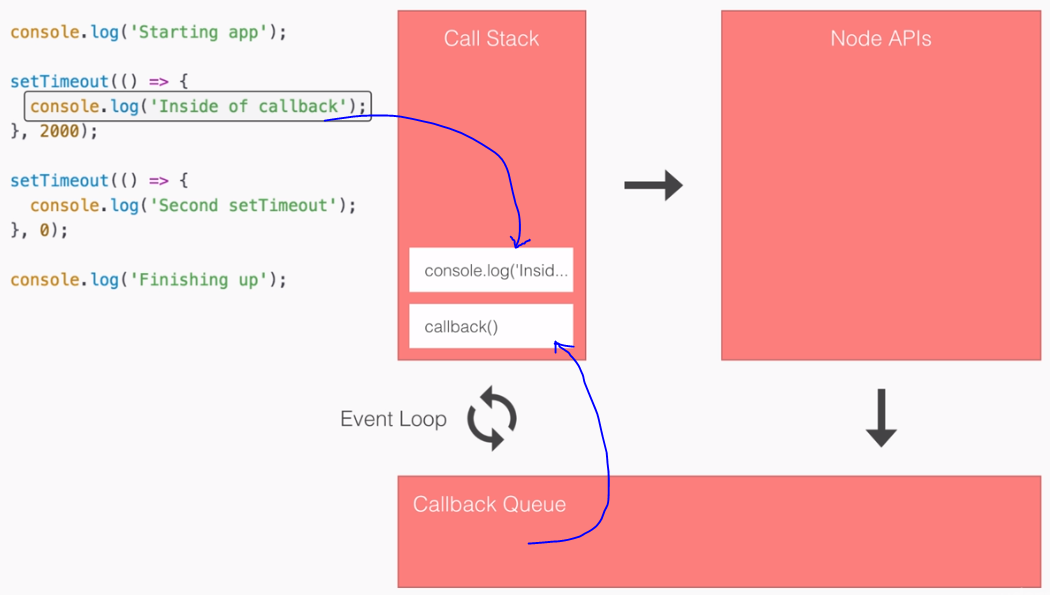
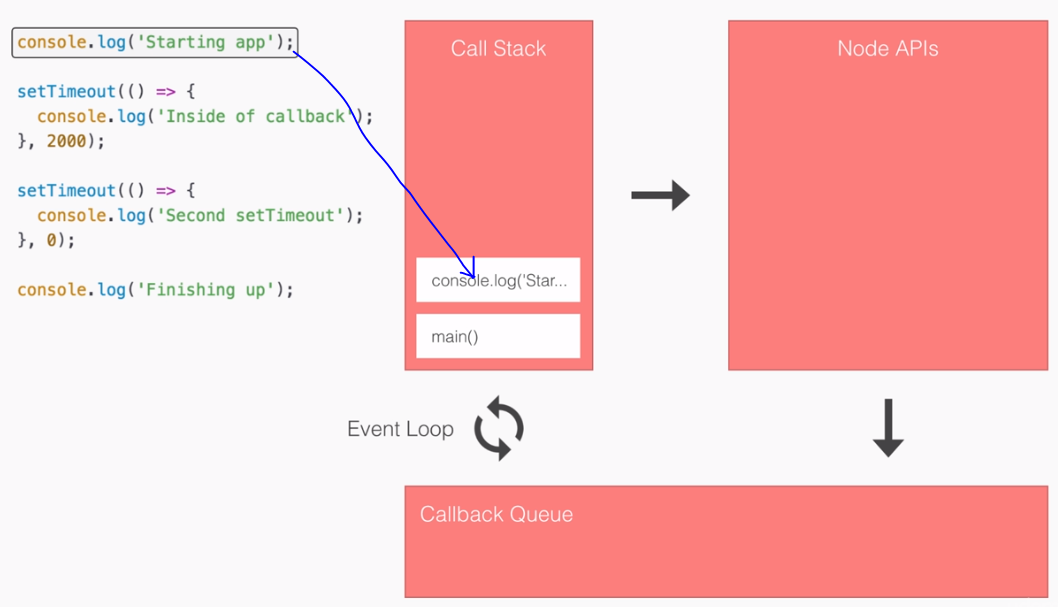
- SPA: Angular2 builds Single Page Applications : SPA technology is generating high interest in the software industry because of its potential for better-performing browser and smartphone applications.
- If you want to see a Single Page Application in action, click https://angular-university.io and start clicking on the home page on the list of latest courses, and on the top menu.
- If you start navigating around, you will see that the page does not fully reload – only new data gets sent over the wire as the user navigates through the application – that is an example of a single page application.
- Advantages
- Production Deployment - A SPA is super-simple to deploy if compared to more traditional server-side rendered applications: it's really just one index.html file, with a CSS bundle and a Javascript bundle. Of course the application will need to make calls to the backend to get its data, but that is a separate server that can be built if needed with a completely different technology: like Node, Java or PHP.
- Versioning & Rollback: All we have to do is to version our build output (that produces the CSS and JS bundles).
- Best User Experience :
- Avoid the constant full page reloads as in traditional web application.Thus much-improved user experience due to less full page reloads and a better overall performance because less bandwidth is needed.
- On a SPA, after the initial page load, no more HTML gets sent over the network. Instead, only data gets requested from the server (or sent to the server).
- So while a SPA is running, only data gets sent over the wire, which takes a lot less time and bandwidth than constantly sending HTML
- More details about SPA is here
SPA & Angular 2:
- An SPA renders only one HTML page from the server, when the user starts the app.
- Along with that one HTML page, the server sends an application engine to the client. I.e.
- In a SPA after application startup, the data to HTML transformation process has been moved from the server to the client – SPAs have the equivalent of a template engine running in your browser
- This engine controls the entire application including processing, input, output, painting, and loading of the HTML pages.
- Typically, 90–95 percent of the application code runs in the browser; the rest works in the server when the user needs new data or must perform secured operations such as authentication.
- Because dependency on the server is mostly removed, an SPA autoscales in the Angular 2 environment.
- No matter how many users access the server simultaneously, 90–95 percent of the time the app's performance is never impacted.
What is Angular 2?
- Is a client-side JavaScript MVC framework to develop a dynamic single-page web application.
- Angular is a TypeScript-based Open-source Front-end Web Application Platform led by the Angular Team at Google.
- Angular was originally started as a project in Google, but now it is an open source framework.
What is Advantages of Angular 2?
- There is many more advantage of Angular 2.
- The Angular 2 has better performance as explained above (Heavy Loading At Client Side, Separate Application & Rendering Layer)
- The Angular 2 has more powerful template system.
- The Angular 2 provide simpler APIs, lazy loading and easier to application debugging.
- The Angular 2 much more testable.
- The Angular 2 provides to nested level components.
- The Angular 2 execute run more than two programs at the same time
Angular 2 Major Building Blocks:
- Module
- Angular applications are modular. Every Angular application has at least one module— the root module, conventionally named AppModule.
- As the developer, it's up to you to decide how to use the modules concept. Typically, you map major functionality or a feature to a module.
- Let's say you have five major areas in your system. Each one will have its own module in addition to the root module, totaling six modules.
- Component -
- A component controls a patch of the page, called a view.
- A component contains a class, a template, and metadata. A template is a form of HTML that tells Angular how to render the component. A component can belong to one and only one module.
- All of the components that are used must be made known via bootstrap. They also have to be imported on the page.
- Services/Observable Services
- A service provides any value, function, or feature that your application needs.
- Components are big consumers of services. Services are big consumers of microservices.
- Routes:
- Routes enable navigation from one view to the next as users perform application tasks.
- A route is equivalent to a mechanism used to control menus and submenus.
- Component Interaction (Using @Input & @Output)
- Template
- Data Binding
- Directive
- Dependency Injection
- Pipes
- Guards (To guard Route/Child Route)
- Resolvers (To load object, before route is activated)
- AOT (Ahead of Time Compiler)
- Faster Rendering
- Smaller Angular Framework download size (typically vendor.ts)
- Better Security (becoz of no html download which reduceds possibiltity of HTML Injection)
- Early Template Errors detection
- Fewer Async Calls to Server
Angular 4 - Updates & New Features:
- View
Engine With Less Code -
Reduced it’s bundled file size by 60%. - The code generated is reduced and
has accelerated the application development. Here the developed code can
be used for prod mode and debug.
- ngIf with a new else
statement -
- Template - '
ng-template' tag will be utilized rather than the just 'template' tag - Http: Adding search parameters to
an HTTP request has been simplified.
- Pipes: Angular 4 introduced a new
pipe - titlecase : It changes the first letter of each word into
uppercase.
- More compatible with newer versions TypeScript
2.1 and TypeScript 2.2. This helps with better type checking and also enhanced IDE features for Visual Studio Code.
- Router ParamMap -
- Before,
simple object structures used to store route parameters - These Parameters were assessed by simple
standard JavaScript syntax : (parameterObject[‘parameter-name’] )
- But now
in Angular 4, these parameters are available as a map. To use these parameters simple methods are called - (parameterMap.get(‘parameter-name’))
- Module-ID Removed: Used
to resolve relative paths for your stylesheets and templates. Angular4
added a new SystemJS plugin (systemjs-angular-loader.js) to SystemJS
configuration. This plugin dynamically converts
"component-relative" paths in templateUrl and styleUrls to
"absolute paths".
- Animation
Package Seperated - Animation functions were provided as a part of
@angular/core module (whether you need or not). Now animation is part of a
separate package. This has eliminated the unnecessary bundles with large
sized files.
Angular 5 - Updates & New Features:
- TypeScript 2.4 support - String-based Enums, Weak-Type-Detection (Types are weak if they only own optional parameters) etc.
- Forms - Earlier validation is performed potentially with every keystroke - Thus worse performance. Now you can specify when validators should be executed in forms. You can select change, which specifies the previous behavior, submit or blur.
- HttpClient - Introduced with Angular 4. Now supports a parameter object for headers and parameters.
- Router - Extended with additional events. E.g., show progress when a route is changed. The corresponding events are ActivationStart and ActivationEnd or ChildActivationStart and ChildActivationEnd.
- Animations - Extended with several syntax ingredients. It is now possible to respond to numerical value changes by using :increment and :decrement in order to animate according transitions.
Angular 6 - Updates & New Features:
- Ivy – The New Rendering Engine (Third Engine so far). Only noticeable thing is application being more nimble and responsive.
- Locality - Locality allows for more flexibility, and the Angular 6 updates mean that developers no longer have to tediously compile a specific library into an AOT.
- Tree Shaking - Tree shaking is a tool for optimizing the building process. It attempts to prevent unused lines of code from ending up in the final product. The Ivy renderer greatly improves the tree shaking process. Instead of making use of an interpreter, the new renderer will create template information directly. What this means is that bundles are much smaller and startup time should be super fast.
- ng update - Feature that allows for automatic updates of Angular dependencies in the package.json file. The ng update is an attempt to improve bug detection, updating the code without manual command. (e.g. ng update @angular/core)
- ng add - Provides you a seamless way to add new functionalities to an application.It works the same as npm, but it doesn’t replace it. (e.g. ng add @angular/elements)
- TypeScript 2.7 & RxJS 6 - Angular 6 now depends on TypeScript 2.7 and RxJS 6. RxJS 6 has new and simpler import paths and gets away with chainable operators in favor of pipeable operators. This makes the library as a whole more tree-shakable and will result in smaller bundles. RxJS 6 contains some breaking changes, but a new package, rxjs-compat, can be installed alongside RxJS 6 to provide a compatibility layer while upgrading your code to the new syntax.
Angular 7 - Updates & New Features:
- Updates regarding Application Performance
- Angular Material & CDK,
- Virtual Scrolling,
- Improved Accessibility of Selects,
- Content Projection using Web standard for custom elements,
- Dependency updates regarding Typescript 3.1, RxJS 6.3, Node 10
Angular 8 - Updates & New Features:
- Featuring Differential loading for all application code,
- Dynamic imports for lazy routes,
- Web workers,
- TypeScript 3.4 support,
- Angular Ivy as an opt-in preview - Includes Below
- Generated code that is easier to read and debug at runtime
- Faster re-build time
- Improved payload size
- Improved template type checking
- Backwards compatibility
Angular 9 - Updates & New Features:
- Moved all applications to use the Ivy compiler and runtime by default.
- Angular has been updated to work with TypeScript 3.6 and 3.7.
- In addition to hundreds of bug fixes, the Ivy compiler and runtime offers numerous advantages:
- Smaller bundle sizes
- Faster testing
- Better debugging
- Improved CSS class and style binding
- Improved type checking
- Improved build errors
- Improved build times, enabling AOT on by default
- Improved Internationalization
Angular 10 - Updates & New Features:
- New Date Range Picker (Material UI library)
- Warnings about CommonJS imports
- Optional Stricter Settings
- Keeping Up to Date with the Ecosystem
- New Default Browser Configuration
- Deprecations and Removals
Angular 11 - Updates & New Features:
- Available With Typescript 4.0, Webpack 5
- Updated Hot Module Replacement (HMR) Support
- Updates on Operation Byelog
- Automatic Inlining of Fonts
- Component Test Harnesses
- Updated Language Service Preview
- Faster Builds
- Experimental Webpack 5 Support
- Moving to ESLint.
Angular 12 - Updates & New Features:
- Available With Typescript 4.2, Webpack 5
- Ivy Everywhere: Angular v12
- Migrating from legacy i18n message IDs
- Protractor: planning for future
- Nullish Coalescing
- Improvements in styling
- Deprecating support for IE11
Angular CLI over WebPack:
A bundler is software that bundles your application code along with its resources into a minimized, zipped bundle that can be easily deployed on the server.
There are many bundlers out there, most widely used are Grunt, Gulp and lately, Webpack.
While Grunt and Gulp simply bundle all js files and all assets, Webpack does extra:
A bundler is software that bundles your application code along with its resources into a minimized, zipped bundle that can be easily deployed on the server.
There are many bundlers out there, most widely used are Grunt, Gulp and lately, Webpack.
While Grunt and Gulp simply bundle all js files and all assets, Webpack does extra:
- Maintains a dependency tree (by scanning import statements) and that allows it to only bundle resources and js files your code actually uses,
- Identify chunks of code – using code splitting – and bundle chunks together for a more efficient bundle.
- It has Webpack under the hood, already pre-configured, so you enjoy the benefits without the hassle of configuration.
- It is very easy to use with a set of cli commands, the main ones are:
- ng new – create a new angular-cli enabled project
- ng init – initialize the current project for angular-cli
- ng test – run all unit tests (using karma/jasmine stack)
- ng e2e – run all protractor e2e tests
- ng serve – will run your app in a local web server
- ng build – will compile TypeScript code, bundle the dependency tree and dump it to the dist folder.
- ng build --prod – will also minify, zip, hash etc.
- It comes with a code generator – you can use it to create skeletons of the most common ones (Components, Directives, Services and Pipes) by simply using the cli command ng g
.
Reference: Link1
TypeScript:
- TypeScript is a form of JavaScript which knows types and classes and can be compiled to JavaScript.
- It is open source. TypeScript includes many aspects of object orientation such as Lambdas, Iterators, Inheritance, Generics, Interfaces etc.
- TypeScript is an extension of ECMAScript, in fact: TypeScript = ES6 + Types + Annotations
- TypeScript is a superset of ECMAScript 6 (ES6), and is backwards compatible with ECMAScript 5 (i.e.: JavaScript)
- In previous versions of ECMAScript, everything was still defined by a JS prototype. Now classes are defined and it makes it almost as readable as Java code.
- TypeScript is actually from Microsoft, which means the new Angular is also likely to be popular for .NET developers.
- TypeScript Concepts
- Variables
- Let vs Var
- Const
- Functions
- Overloading
- Arrays
- Destructuring
- Type Guards
- Type Assertions
- Tuple
- Interfaces
- Classes
- Static vs Read-only
- Generics
- Inheritance
- Namespace
- Module


- ngOnChanges: Called after a bound input property changes
- ngOnInit: Called once the component is initialized (After Constructor)
- ngDoCheck: Called during every change detection run
- ngAfterContentInit: Called after content (ng-content) has been projected into view
- ngAfterContentChecked: Called everytime the projected content has been checked
- ngAfterViewInit: Called after the component's view (& child views) has been initialized
- ngAfterViewChecked: Called everytime the component's view (& child views) has been checked
- ngOnDestroy: Called once the component is about to be destroyed
Ref:
- https://magenic.com/thinking/angular-2-vs-angularjs-1-which-to-choose
- https://www.angularminds.com/blog/article/comparison-difference-between-angular1-vs-angular2-vs-angular4.html
- https://dzone.com/articles/typed-front-end-with-angular-2
- https://www.code-sample.com/2016/06/angular-2-interview-questions-and.html
- With Code:
- https://www.infoq.com/articles/Angular2-TypeScript-High-Level-Overview
- https://www.ibm.com/developerworks/library/wa-implement-a-single-page-application-with-angular2/index.html
Hope this helps!!
Arun Manglick











{kind=link}